Meta, one of the founding members of Overture Maps Foundation, has successfully transitioned its suite of global basemaps used across apps such as Facebook and Instagram to Overture’s base data layers
The goal was to build an up-to-date, validated, global basemap using OpenStreetMap that could power all of Meta’s use cases. Daylight included validation checks designed to find and correct mapping errors, building footprint detections, lidar derived building heights, name translations, and a global land cover layer. This global dataset was made publicly available and has served the maps at Meta for the past five years.
As a founding member of Overture, Meta has been deeply involved in developing the processes that produce Overture’s published data. In fact, the very same validation processes and pipelines that were used in Daylight are also now used to produce Overture’s regular data releases.
Notice the past tense. There is no official announcement confirming Daylight’s end of life. But there hasn’t been an update since November 2024 after more than four years of at least twice-monthly releases.
Update (30 April 2025):Daylight has indeed reached its end of life. I missed the announcement in May last year, and then again, when I was looking for an official statement while writing this post, I didn’t see the update buried in between all the data updates.
One of the important new features in this release is the introduction of Global Entity Reference System (GERS) IDs. GERS IDs have been assigned to over 1.6 million building footprints across several cities in North America, South America, and Europe.
GERS is a system of encoding map data to a shared universal reference, which provides an easy mechanism to conflate data from different data providers based on a specific GERS ID.
Overture introduced GERS recently; it aims to provide a globally unique reference for every entity that can be mapped. It appears, the idea is that data providers outside of Overture can enrich their data sets with GERS to increase interoperability and ease the effort required to fuse data. An enticing idea, sure, but it seems GERS is of little use outside of Overture’s ecosystem.
Let me explain.
In order to retrieve and enhance a data set with GERS IDs, you have to match your data to Overture’s using geometry intersections. This works, but it’s not a novel approach. We were able to do spatial joins before, and IDs also existed before. If a feature is not yet part of Overture’s data, then the only way to create a GERS ID is to add it to Overture’s data set. GERS practically doesn’t exist outside of Overture data.
And questions remain how GERS keeps up with changing data. What if I knock down my house and build a new one at the same place? Does the original GERS ID continue, or is this a new one. What if I subdivide my property; does this result in two new GERS IDs, or is the existing one applied to one part? How about I buy the property next door and connect the two house so they become one?—New GERS ID or one of the original ones? And what if the GERS ID for an entry changes? How do I keep track of these changes to update the IDs in my dataset? If we look at GERS as a gateway to keep datasets in sync, then these are crucial questions to answer.
It’s early stages and I’m sure there are discussions within Overture to address these concerns. But for now, GERS’ only application will be conflation of data from Overture data donors to produce their building datasets.
Mapstack doesn’t tie in with existing tools. Currently, there is no tooling to create or manage data, collaborate or visualise the data. It’s a place where the result of data processing might be hosted. Open data providers have invested in the infrastructure to host data—it’ll be hard to convince them to migrate to Mapstack instead.
I have similar thoughts about Source. These data repositories can be useful for providers of small-scale datasets who don’t want to run their own infrastructure, but I question whether we’ll see large, global datasets on these repositories. But Source already hosts several substantial datasets from big names such as NASA, ESA, or CGIAR, presumably because of well-established networks by the people involved in building Source—I have been wrong about these things before.
Currently it’s hard to understand what data is available on Source without paginating through all datasets. The platform lacks advanced search functionality that lets me look for data by geographic region, data format, or time. And to preview the data, I have to download it first and use third-party tooling. A map or table preview on the website would be far more convenient for people to explore data. (Both of these features are on the Source’s roadmap.)
My colleague Wille Marcel looked at Overture’s data quality, specifically considering the confidence score that is included in the data:
This analysis shows that the Overture Places dataset can be quite useful when filtered by a 0.6 confidence threshold. The main quality issues we observed are the inaccurate location of many items and outdated places.
This matches my experience with the data. In my area, the location accuracy could be better; many businesses are located outside their buildings, in the middle of the road, the backyard, some even on the beach. And the data includes some businesses that have since closed.
Ahead of Google Cloud Next 23, the company announced new map data sets available through the Google Maps API.
Now we’re expanding our sustainability offerings with new products in Google Maps Platform. These products apply AI and machine learning, along with aerial imagery and environmental data, to provide up-to-date information about solar potential, air quality and pollen levels. With this technology, developers, businesses and organizations can build tools that map and mitigate environmental impact.
The SolarAPI helps building owners and developers estimate potential energy savings by leveraging solar power. Using imagery, LIDAR data and 3D models, the data provides insights on the solar potential of a building and aids the design of solar systems. The data covers 40 countries.
While data from the Solar API can help tackle the causes of climate change, the Air Quality and Pollen APIs help humans mitigate its effects.
Based on a model that takes in land cover, climate data, pollen-production rates from various plant species, the Pollen API provides estimated pollen counts for 15 plant species in 65 countries. The Air Quality API combines data from various sources, including “government monitoring stations, sensors, models, meteorological data, satellites, land cover, and live traffic information,” to create a air-quality layer covering 100 countries.
James Killick collecting some damning anecdotes about the quality of crowdsourced data on Google Maps.
There are unregistered Taxi services listed at Heathrow airport.
Upon that I was shown a Google map of LHR Terminal 5 with an icon for “Bob’s Taxis” right there in the middle of the arrivals area. Not good.
[…]
Yes, dear readers, the dreaded unlicensed taxi cab service is still there. It’s no longer called “Bob’s Taxis” and it now sounds a lot more official, but hey — I pity the poor passengers that fall for this.
After a minute the line broke up, but they called me back… from the number +33-4-56-38-67-82 (French number that came up as DTI Publishing in Caller ID). First Red flag. He had a very strong Indian Accent (Red Flag), and was overly eager to help me
I usually try to find critical information on the business’ website instead of Google Maps; not because of scammers but because I don’t trust that businesses update their information on Google Maps.
I’ve been using Apple Maps for a while now for my personal way finding needs and I’ve had only positive experiences. So far I’ve never encountered incorrect information and the map is less littered with irrelevant data.
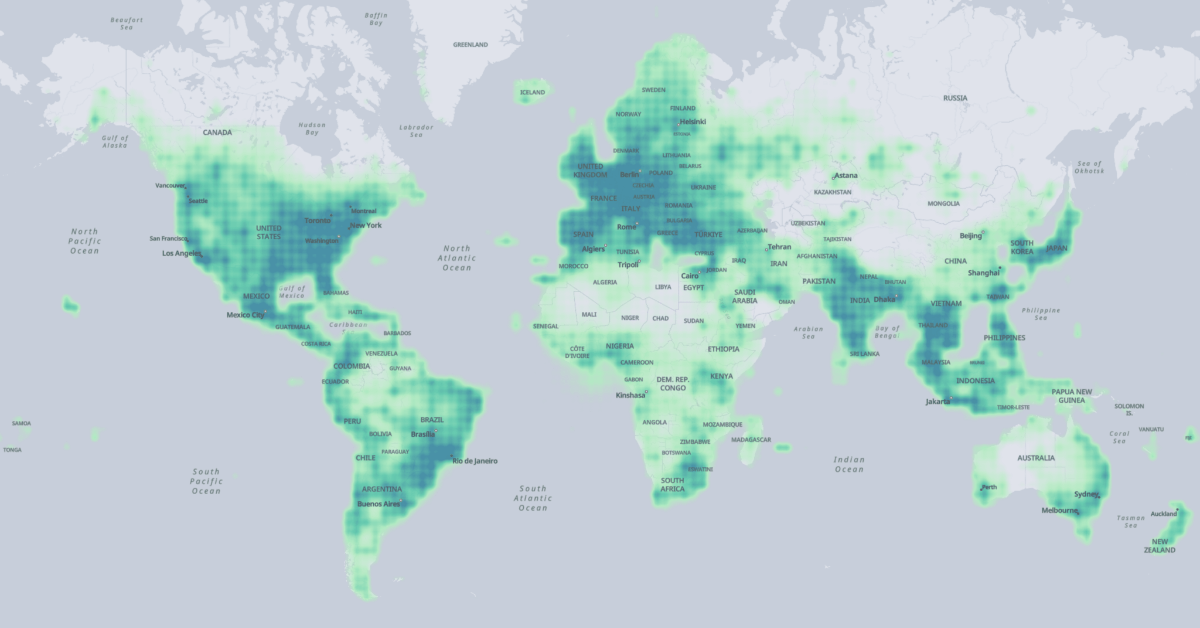
The extent of the Overture Map Foundation's places data across the globe. (Source: Overture Map Foundation)
The four layers combine data from different sources into one uniform data schema. The data has been sourced from commercial data provides, all members of the foundation, and and OpenStreetMap:
Meta contributed to places of interest,
Microsoft contributed to places of interest and buildings,
Esri contributed to buildings, and further
Buildings and transportation data was sourced from OpenStreetMap.
Accordingly the licenses vary for each data layer:
Places of interest and administrative boundaries are licensed under CDLA Permissive v2.0; the data can be modified and shared as long as the original license is included.
The buildings and transportation layers are available under ODbL, which the same as OpenStreetMap’s license.
The data is hosted on AWS S3 and Azure Blob Storage and available for download in the Parquet format, a cloud-native format. You can download the data to your local machine using the AWS CLI, Azure Storage Explorer or the AzCopy.
Alternatively, to make use of Parquet’s cloud-native capabilities to download only the data you need, you can fetch data via SQL queries in AWS Athena, Microsoft Synapse, or DuckDB.
The data release is the first major sign that the the Overture Maps Foundation is alive and produces results. Combining sources from major providers could yield one of the most complete and up-to-date data sources we currently have; it would be interesting to see how it compares to OpenStreetMap. Plus the use of modern, cloud-native formats make this vast dataset manageable, without clogging up your hard drive.
The data was created from high-resolution satellite images, using machine learning. As such, it only contains only the building geometry, data that can be derived from the building footprint (centroid, area, it the Plus code), and the level of confidence in the mapping. However, no further information about a building are available, like its height, building type, or address.
You can download the data in CSV format, one file per S2 level 4 cell, with the building polygons in WKT. Other common geospatial formats are not available and additional processing and data ingestion may be required for many use cases.
Google announced that their 3D tiles will be available through the Map Tiles API. Surprisingly, the API isn’t a proprietary design but implements the OGC 3D Tiles standard, which opens the dataset up for visualisations using open-source client libraries such as Cesium or Deck.gl.
You have to register with Google and provide an API key to use Google’s 3D Tiles. The service is free, for now, during its experimental stage.
The Geofabrik Shapefiles have been a go-to resource ever since for OpenStreetMap data in GIS-friendly formats. Geofabrik now also offers vector-tile downloads for individual countries in Europe and states in the US.
At this time, the service is experimental, with no timeline for a stable and regularly-updated product:
This is supposed to be an experiment and we don’t yet make any promises about the structure and update frequency of this offer. We’re happy to hear your ideas though.